






5 faktów o ChatGPT, GPT, LLM. Sztuczna inteligencja od kuchni
Nazwa ChatGPT jest ostatnio odmieniana przez wszystkie przypadki. Tysiące porad, hipotez i infografik publikowanych każdego dnia w mediach społecznościowych przez początkujących ekspertów sprawiło, że bardzo trudno jest rozróżnić jakość tych informacji oraz "przykryć" istotę użycia tej przełomowej technologii w biznesie. Spróbujmy zatem dokładniej przyjrzeć się tzw. dużym modelom językowym (ang. large language models), do których m.in. należy GPT-3, czyli silnik chatbota, jakim jest ChatGPT.
Fakt 1: ChatGPT to nie to samo co GPT-3
Zaczniemy od bardzo ważnego faktu: ChatGPT i GPT-3 to nie to samo. GPT-3 to duży model językowy (z ang. w skrócie LLM) stworzony za pomocą architektury głębokiego uczenia typu Transformer (zaraz do niej wrócimy). Modele LLM są cyfrowymi odpowiednikami człowieka z pamięcią fotograficzną, który przeczytał wszystkie książki oraz publikacje tekstowe, np. artykuły, ustawy, wzory dokumentów, badania naukowe.

Natomiast ChatGPT to chatbot (oprogramowanie) wykorzystujący GPT-3 (dokładnie 3.5), wyposażony w dodatkowe techniki uczenia maszynowego, takie jak uczenie nadzorowane oraz uczenie przez wzmocnienie na podstawie opinii użytkowników (ang. reinforcement learning from human feedback). OpenAI w oficjalnych materiałach określa ChatGPT jako zoptymalizowany model językowy przeznaczony do dialogów. Jakbyśmy go nie nazywali – czy to bardzo inteligentny chatbot wykorzystujący LLM, czy też zoptymalizowany model – to jest to zupełnie inny produkt. Co ważne, ChatGPT posiada od niedawna API (to skrót od Application Programming Interface, czyli Interfejsu Programowania Aplikacji - przyp. red.); jednak komunikacja z nim odbywa się w formie dialogu, czyli bardziej w stylu komunikacji człowiek-system. Natomiast GPT-3 (173 miliardy parametrów) i inne modele LLM są przystosowane do komunikacji system-system m.in. dzięki dodatkowym parametrom już ściśle technicznym (np. temperatura - dzięki której sterujemy kreatywnością odpowiedzi), czyli są gotowe do zaawansowanych wdrożeń biznesowych.
Co ważne, jeśli chcemy, aby ChatGPT rozwiązał nam pewne zadanie, to opisujemy je w formie dialogu, jak na czat przystało. Natomiast GPT-3 (jak również inne LLM) sterujemy za pomocą prostych komend i wskazówek (tzw. prompts) wysyłanych przez specjalny interfejs programistyczny. Zatem GPT-3 bardziej będzie wykorzystywany przez inne aplikacje (od biurowych po sklepy internetowe i systemy CRM) niż bezpośrednio przez ludzi.
Dlatego Microsoft wykorzystał model GPT-3 w swoich Teamsach do generowania automatycznych notatek, ekstrakcji zadań i identyfikacji osób. Należy jednak zwrócić uwagę, że wykorzystano model GPT-3, a nie ChatGPT. Natomiast ChatGPT został dodany do wyszukiwarki Bing przez firmę z Redmond, jednak do tego tematu jeszcze wrócimy.
![Fakt 2: GPT-3 nie jest to jedyny [MK1] [SK2] model tego typu na świecie! Inteligentne podsumowanie spotkań w oprogramowaniu Microsoft Teams, czyli GPT-3 w akcji. [dostęp 08.02.2023].](https://v.wpimg.pl/YWE4NjBldjYkVjhZbRd7I2cObAMrTnV1MBZ0SG0PdmF1BjZZcVV2MSxYKxgnHDZ5IkY7GiMbKXk1WGELMgV2IXQbKgMxHDU2PBsrByAJPXgkBShcdl07NmgFflMhQW0zJFZjU3ZVYXonBHdYcA04b3MEKw9gEQ)
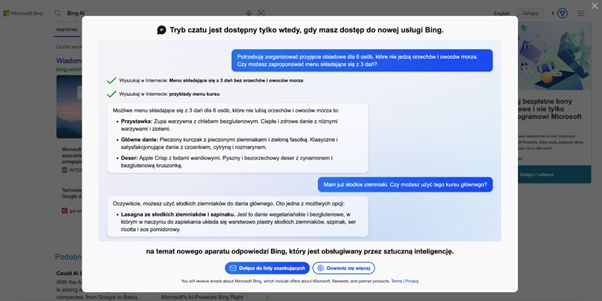
Fakt 2: GPT-3 nie jest to jedyny model tego typu na świecie
Zatem, gdy jak znamy różnicę pomiędzy GPT-3 a ChatGPT, możemy przejść do następnego istotnego faktu: GPT-3 to nie jedyny, ani nawet największy, lecz jeden z wielu wytrenowanych modeli językowych na ogromnych bazach publikacji tekstowych (LLM). Aby zrozumieć, skąd się te modele wzięły, musimy cofnąć się do 2017 roku, kiedy naukowcy z działu badawczego Google i Uniwersytetu Toronto opublikowali artykuł "Attention Is All You Need", w którym przedstawili "prostą" architekturę Transformer opartą na mechanizmie uwagi (self-attention). Architektura ta była dedykowana do danych sekwencyjnych, takich jak teksty. Dlaczego uwaga jest tak ważna? Ponieważ pozwala skupić się człowiekowi na najważniejszych słowach lub fragmentach nawet długich wypowiedzi i wykorzystać to, co dla niego najważniejsze. Dlaczego więc nie naśladować tego w algorytmie głębokiego uczenia?
Dalsza część artykułu pod materiałem wideo
14.03 Program Money.pl | Czytelnictwo w erze cyfrowej. Czy jest kryzys?
W ciągu trzech miesięcy po opublikowaniu artykułu na rynku pojawiły się pierwsze modele LLM, tj. ELMO (luty 2018) Instytutu AI im. Paula Allena i Uniwersytetu Waszyngtońskiego, GPT-1 (czerwiec 2018) OpenAI, BERT (listopad 2018) Google'a, GTP-2 (luty 2019) OpenAI oraz GPT-3 OpenAI (czerwiec 2019). Jak widać, obok OpenAI (twórcy GPT-3) bardzo duży wkład ma również Google. Obecny krajobraz jest jeszcze bardziej rozbudowany, ponieważ istnieją na rynku zarówno otwarty model GPT-NeoX organizacji open science EleutherAI, jak i przygotowany do zastosowań biznesowych model Cohere. Nie można zapomnieć o największych modelach PaLM (540 miliardów parametrów, Google) oraz MT-NLG (530 miliardów parametrów, Nvidia i Microsoft).
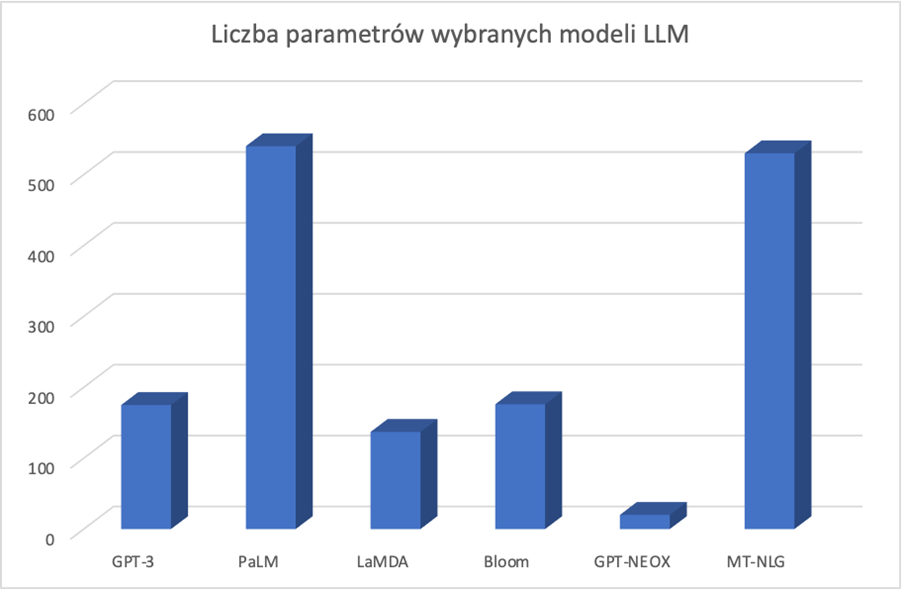
Liczba parametrów dużych modeli językowych (opis wykresu poniżej)
Co oznaczają liczby parametrów LLMów podawane przez media i producentów, np. GPT-3 – 175 miliardów parametrów? Są to parametry sieci neuronowej, a dokładniej liczba wag. Nie będziemy wchodzić w szczegółową analizę architektury sieci neuronowych, liczby neuronów, połączeń, warstw i roli wag w tej całej neurologicznej maszynerii. Jednak ważne jest, że im większa liczba parametrów (wag), tym bardziej złożony jest model i potencjalnie dokładniejszy może być model językowy. A jak lepsza dokładność, to możemy powiedzieć, w dużym uproszczeniu, że model jest mocniejszy. Zatem trudno dziwić się, że PaLM i MT-NLG nazywane są największymi i najmocniejszymi modelami językowymi, co oznacza, że posiadają największą liczbę parametrów sieci neuronowych (wag) i co wymagało ogromnych baz tekstów do ich wytrenowania liczonych w terabajtach.
Fakt 3: Prompt engineering umiejętność przyszłości
Co spowodowało, że duże modele językowe są tak często wykorzystywane niezależnie od tego, czy zastosowano je w ChatGPT, czy w wielu użytecznych aplikacjach (CopyAI, Jasper.ai, PolyAI) lub systemach (np. QuickChat)? Dzięki ogromnemu "oczytaniu" modele potrafią rozwiązywać większość zadań związanych z tekstem, od generowania tekstu, tłumaczenia maszynowego, korekty językowej, streszczenia, aż po odpowiadanie na pytania. Oprócz tej wielozadaniowości komunikacja z modelem nie przebiega za pomocą skomplikowanych technicznych połączeń API, lecz za pomocą języka naturalnego. Po prostu wysyłamy mu opis zadania: "przetłumacz poniższy tekst na język angielski". Czasami trzeba pomóc naszemu modelowi, pokazując mu na przykład, kontekst oraz czego oczekujemy na wyjściu. Wszystko w języku naturalnym, tak jakbyśmy pomagali w pracy młodszemu koledze. Dzięki temu w branży pojawiła się definicja nowej umiejętności (a czasami nawet określenie zawodu przyszłości) tj. prompt engineering, czyli zdolność tworzenia wskazówek i podpowiedzi dla dużych modeli językowych, aby skutecznie rozwiązywały zadania. Zatem agnostyczność zadaniowa oraz prosta komunikacja z modelem za pomocą wskazówek i podpowiedzi to demokratyzacja IT w czystej postaci. Dodając do tego skuteczność, mamy sukces murowany, który właśnie widzimy.
Fakt 4: Microsoft vs Google to dopiero początek wyścigu
Microsoft od dawna wspiera finansowo OpenAI, twórcę GPT-3, ChatGPT, a także Dall-e (generowanie obrazów) oraz Whisper (ekstrakcja tekstu z dźwięku). Z tego powodu zaczął on mocno komunikować swoje plany dotyczące włączania LLM do swoich produktów. Microsoft Teams otrzymał GPT-3, a Bing został rozszerzony o ChatGPT. Wiele osób łączy te premiery z ostatnimi zwolnieniami pracowników w wyszukiwarkowym gigancie i wywołuje przekonanie, że to koniec wyścigu z jednym mocnym przegranym. Jednakże Google posiada jeden z największych modeli LLM na świecie i zapoczątkował rewolucję w modelach generatywnych (patrz architektura Transformer).
Dlatego też rok 2023 będzie rokiem produktywności dla nas jako społeczeństwa, ponieważ w każdym miesiącu pojawią się przełomowe wdrożenia dużych modeli językowych w pakietach biurowych, komunikacyjnych oraz wyszukiwarkach. Google już odpowiedział na ChatGPT, swoim rozwiązaniem Bard, wspartym autorskim modelem LaMDA. Zatem wygląda na to, że zarówno Bing, jak i wyszukiwarka Google, będą miały zupełnie nową funkcjonalność, która najprawdopodobniej zmieni sposób pozyskiwania wiedzy przez internautów. Wyścig zatem nie skończył się, on dopiero się zaczyna, a uczestników będzie znacznie więcej.
Fakt 5: White Collar nie muszą się pakować
Technologia ChatGPT cieszy się mieszanymi opiniami - połowa osób ją kocha, a połowa nienawidzi. W mediach społecznościowych pojawiają się dwa typy komentarzy: "Wow! To świetne narzędzie, [nazwa stanowiska pracy] może się pakować" lub "Gada głupoty, nigdy nie zastąpi [nazwa stanowiska pracy]". Zatem czas rozpocząć dyskusję na temat przyszłości sztucznej inteligencji i jej wpływu na rynek pracy. Po pierwsze, już sama nazwa "sztuczna inteligencja" jest dość nietrafiona. Sztuczna oznacza budowana w celu zastąpienia naturalnej? Czy nie lepiej byłoby jednak pójść w kierunku wzmacniania inteligencji, która nawet akronim ma podobny IA (ang. intelligence amplification) ;-) oraz wiek (wczesne lata 50). W tym nurcie ostatnio pojawił się termin tzw. superzespołów wprowadzony przez Deloitte. Pomysł superzespołów, czyli współpracy ludzi i inteligentnych maszyn w celu rozwiązywania problemów i maksymalizacji wartości biznesowych. Idea ta nie oznacza jednak redukcji pracowników, a wręcz przeciwnie - ich rozwoju. W tym kontekście IA należy postrzegać nie jako zamiennika, a jako współpracownika, który pomoże nam zwiększyć zadowolenie klientów, wypuścić na rynek nowe produkty czy też wypromować firmę.
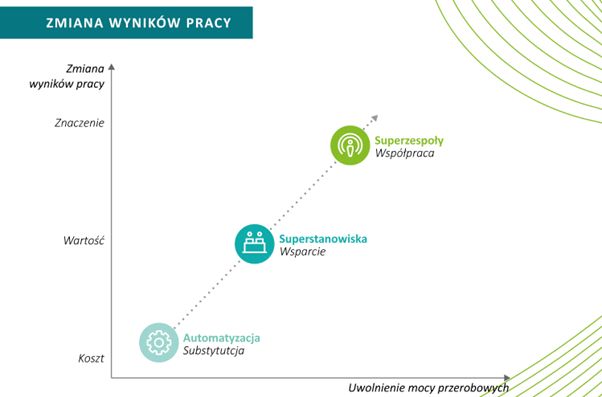
Duże modele językowe, jak sama nazwa wskazuje, są trenowane na ogromnych zestawach danych tekstowych - setek gigabajtów dla jednego języka. Ich wielozadaniowość wynika z różnorodności tekstów oraz specjalizowanego dostrajania. Trudno jest wyjaśnić wszystko za pomocą pięciu wybranych faktów i dziesięciu tysięcy znaków. Jednak ta skrócona dawka wiedzy o ChatGPT, GPT i ogólnie obszarze LLM w postaci analizy najważniejszych faktów z nimi związanych powinna wystarczyć, aby zacząć rozróżniać tzw. "ekspertów" od ekspertów. Co ważniejsze, abyście dodatkowo spojrzeli na te przełomowe technologie z innej perspektywy. Jeśli szukacie przypadku użycia, by wykorzystać je w swojej firmie, skupcie się bardziej na dużych modelach językowych, takich jak GPT-3, Bloom, Cohere czy GPT-NEOX, lub ich biznesowych implementacjach, np. w postaci AI Writing Assistant, niż na chatach Bard czy ChatGPT. Podczas ewentualnych analiz wykorzystania modeli skupcie się zarówno na oszczędnościach (zwłaszcza długofalowo), jak i na celach związanych z maksymalizacją wartości biznesowych.
Nie bójcie się także samodzielnie przetestować LLMów - prawie każdy dostawca (OpenAI, Cohere, NlpCloud) posiada tzw. piaskownice i obszerne samouczki, a prompt engineering pozwoli wam przetestować wasze najbardziej szalone pomysły biznesowe. Natomiast, jeśli coś w artykule było niezrozumiałe, albo chcielibyście uszczegółowić jakiś temat lub potrzebujecie więcej porad dotyczących promptów, nic trudnego - wtedy zapytajcie ChatGPT, (wkrótce) Barda lub skontaktujcie się z nami.
Autorami artykułu są: Sebastian Kondracki, Chief Innovation Officer w firmie Deviniti oraz Piotr Jaworski, Head of Sales w Deviniti.
Artykuł powstał w ramach merytorycznej współpracy Akademii Biznesu i Deviniti.











